
هرآنچه دربارهی کارت گرافیکهای RTX 40 میدانیم
انویدیا (Nvidia) روی نسل جدید کارتهای گرافیک خود کار میکند و انتظار میرود این کارتها زودتر از آنچه پیشبینی شدند عرضه شود. طبق اطلاعات به دست آمده، به نظر میرسد کارتهای گرافیک RTX 40 توان ...
منتخب سردبیر

۱۰ بازی که اساطیر کهن را با المانهای علمی تخیلی پیوند زدند
نوشته شده توسط احسان حسین خواه | ۶ مرداد ۱۴۰۵
















انویدیا (Nvidia) روی نسل جدید کارتهای گرافیک خود کار میکند و انتظار میرود این کارتها زودتر از آنچه پیشبینی شدند عرضه شود. طبق اطلاعات به دست آمده، به نظر میرسد کارتهای گرافیک RTX 40 توان پردازشی و عملکردی دو برابری نسبت به سری RTX 30 خواهند داشت.
GeForce RTX 30 که سری فعلی انویدیا است جهش قابل توجهی در عملکرد نسبت به سری RTX 20 ارائه داد و شایعات نشان میدهند که میتوانیم شاهد چنین جهشی از نسل بعدی انویدیا یعنی سری RTX 40 باشیم. در حال حاضر این سری پشت درهای بسته در Nvidia HQ در حال توسعه است.

آخرین شایعات درباره RTX 40 به گره پردازشی ۵ نانومتری با معماری GPU Ada Lovelace اشاره دارد که میتواند جهش دو برابری در عملکرد را ارائه دهد. در این مقاله هر چیزی که درباره Nvidia GeForce RTX 40 Series در حال حاضر موجود است از شایعههای مربوط به این کارتهای گرافیک تا اطلاعات درز شده راجب آنها را توضیح میدهیم.
معماری Ada انویدیا
A100 موتور پلتفرم مرکز داده انویدیا است که توسط معماری Ampere (معماری فعلی انویدیا) طراحی شده است و به طور رسمی در ماه می (May) ۲۰۲۲ معرفی شد و پردازندههای گرافیکی مصرفی Ampere در قالب RTX 3080 و RTX 3090 حدود چهار ماه بعد عرضه شدند.
اگر انویدیا برنامهای مشابه به این با پردازندههای گرافیکی معماری Ada Lovelace داشته باشد، میتوان انتظار داشت که سری RTX 40 در ماه آگوست یا سپتامبر عرضه شود. بیایید به جزئیات و بررسی مشخصات شایعه شده برای سری پردازندههای گرافیکی Ada شروع کنیم.
| GPU | AD102 | AD103 | AD104 | AD106 | AD107 |
| فناوری فرآیند (Process Technology) | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N |
| تعداد ترانزیستورها | B۶۰؟ | B۴۰؟ | B۳۰؟ | B۲۰؟ | B۱۵؟ |
| جریان چند پردازنده (Streaming Multiprocessors) | ۱۴۴ | ۸۴ | ۶۰ | ۳۶ | ۲۴ |
| هستههای GPU | ۱۸۴۳۲ | ۱۰۷۵۲ | ۷۶۸۰ | ۴۶۰۸ | ۳۰۷۲ |
| هستههای تانسور (Tensor Cores) | ۵۷۶ | ۳۳۶ | ۲۴۰ | ۱۴۴ | ۹۶ |
| RT Cores | ۱۴۴ | ۸۴ | ۶۰ | ۳۶ | ۲۴ |
| سرعت کلاک (GHz) | ۱.۶ - ۲.۰ | ۱.۶ - ۲.۰ | ۱.۶ - ۲.۰ | ۱.۶ - ۲.۰ | ۱.۶ - ۲.۰ |
| کل حافظه نهان L2 | ۹۶ | ۶۴ | ۴۸ | ۳۲ | ۳۲ |
| سرعت VRAM | ۲۱ - ۲۴ | ۲۱ - ۲۴ | ۱۶ - ۲۱ | ۱۶ - ۲۱ | ۱۴ - ۲۱ |
| VRAM Bus Width | ۳۸۴ | ۲۵۶ | ۱۹۲ | ۱۲۸ | ۱۲۸ |
| ROPs | ۱۲۸ - ۱۹۶؟ | ۱۱۲؟ | ۹۶؟ | ۶۴؟ | ۴۸؟ |
| TMUs | ۵۷۶ | ۳۳۶ | ۲۴۰ | ۱۴۴ | ۹۶ |
| TFLOPS FP32 | ۵۹ - ۷۳.۷ | ۳۴.۴ - ۴۳ | ۲۴.۶ -۳۰.۷ | ۱۴.۷ - ۱۸.۴ | ۹.۸ - ۱۲.۳ |
| TFLOPS FP16 (تانسور) | ۴۷۲ - ۵۹۰ | ۲۷۵ - ۳۴۴ | ۱۹۷ - ۲۴۶ | ۱۱۸ - ۱۴۷ | ۷۹ - ۹۸ |
| پهنای باند (GBps) | ۱۰۰۸ -۱۱۵۲ | ۶۷۲ - ۷۶۸ | ۳۸۴ - ۵۰۴ | ۲۵۶ - ۳۳۶ | ۲۲۴ - ۳۳۶ |
| TDP (وات) | ۶۰۰> | ۴۵۰> | ۳۰۰> | ۲۲۵> | ۱۵۰> |
| تخمین قیمت | ۱۰۰۰+ دلار | ۶۰۰ - ۱۰۰۰ دلار | ۴۵۰ - ۶۰۰ دلار | ۳۰۰ - ۴۵۰ دلار | ۲۰۰ - ۳۰۰ دلار |
ما با این فرض که در همه پردازندههای گرافیکی Ada، فناوری فرآیند (Process Technology) از گره ۴ نانومتری TSMC باشد، پیش میرویم که باز هم ممکن است از نظر فنی نادرست باشد. میدانیم که انویدیا در معماری پردازنده گرافیکی Hopper H100 از گره ۴ نانومتری TSMC استفاده میکند، که بیشتر به نظر میرسد یک تغییر در گره ۵ نانومتری TSMC است.
این گره ۵ نانومتری TSMC به طور گسترده در تراشههای گوشیهای هوشمند و لپ تاپ اپل (Apple) استفاده میشود و شایعه شده است که این گرهای است که Nvidia برای Ada استفاده خواهد کرد. همچنین گرهای که قرار است AMD برای برای Zen 4 و RDNA 3 استفاده کند.
البته، نام گره تقریباً به اندازه مشخصات و عملکرد واقعی کارت گرافیک مهم نیست. و مدتهاست که نام گرههای فرآیند ارتباط واقعی با ویژگیهای فیزیکی یک تراشه را ندارد و اکنون فقط بیشتر نامهای بازاریابی هستند.

در حال حاضر تعداد ترانزیستورها بهترین حدس است. ما میدانیم که پردازنده گرافیکی Hopper H100 دارای ۸۰ میلیارد ترانزیستور خواهد بود (که واقعاً یک تقریب است، اما ما با آن کار خواهیم کرد). پردازنده گرافیکی A100 دارای ۵۶ میلیارد ترانزیستور است که دو برابر تعداد تراشه هاله مصرفی GA102 است. ممکن است تعداد ترانزیستورهای GA102 به پردازنده گرافیکی H100 نزدیکتر از GA102 به GA100 باشد به این مفهوم که تعداد ترانزیستورها احتمالا به ۸۰ میلیارد نزدیکتر است تا ۵۶ میلیارد.
بر اساس اطلاعات درز شده که تاکنون دیدهایم، به نظر میرسد معماری Ada انویدیا یک هیولا باشد. در مقایسه با پردازندههای گرافیکی فعلی Ampere، تعداد جریان چند پردازنده (Streaming Multiprocessors) و هستههای مرتبط با آن بسیار بیشتر است، که میتواند عملکرد قابل توجهی را افزایش دهد. حتی اگر توانایی Ada کمتر از آن چیزی باشد که شایعات میگویند، مطمئناً شاهد بالاترین عملکرد GPU حال حاضر خواهیم بود. برای مثال، RTX 3080 در زمان راهاندازی حدود ۳۰ درصد سریعتر از RTX 2080 Ti بود و RTX 3090 حدود ۱۵ درصد دیگر اضافه کرد.
عملکرد محاسباتی Ada
قابل توجهترین تغییر در پردازندههای گرافیکی Ada، تعداد جریان چند پردازنده (Streaming Multiprocessors) یا SMها در مقایسه با نسل فعلی Ampere خواهد بود. AD102 به طور بالقوهای ۷۱٪ بیشتر از GA102 جریان چند پردازندهای را بسته بندی میکند. حتی اگر هیچ چیزی به طور قابل توجه در معماری Ada تغییر نکند، ما انتظار افزایش زیادی در عملکرد داریم.
فناوری NVIDIA Turing Tensor Core یا فناوری هسته تانسور تورینگ از محاسبات با دقت چندگانه برای استنتاج کارآمد هوش مصنوعی بهره میبرد. هستههای تانسور تورینگ طیف وسیعی از دقتها را برای آموزش یادگیری عمیق و استنتاج، از FP32 تا FP16، تا INT8 و همچنین INT4 ارائه میکنند تا جهشهای عظیمی در عملکرد نسبت به پردازندههای گرافیکی معماری NVIDIA Pascal ارائه دهند.
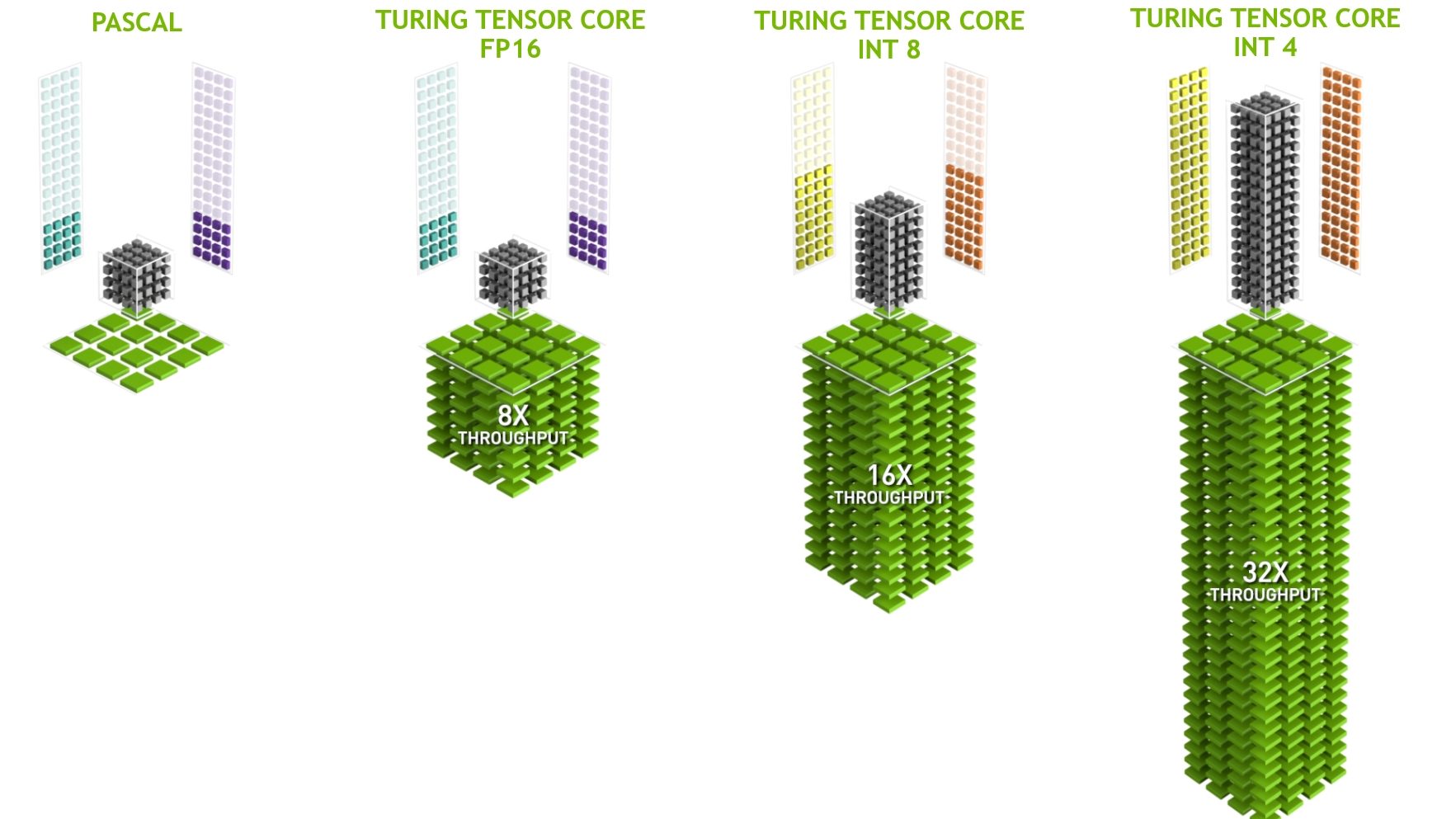
از محاسبات Ampere روی عملکرد هسته Tensor استفاده میکنیم و یک تراشه کاملاً فعال AD102 که با فرکانس نزدیک به ۲ گیگاهرتز کار میکند و میتواند یادگیری عمیق و محاسبات هوش مصنوعی تا ۵۹۰ ترافلاپس در FP16 داشته باشد استفاده میکنیم. GA102 در RTX 3090 Ti در مقایسه با ۳۲۱ ترافلاپس در FP16 (با استفاده از ویژگی پراکندگی انویدیا) بالاتر است.
این یک افزایش تئوری ۸۴ درصدی است که بر اساس شمارش هسته و سرعت کلاک است. فلاپس یا عملیات ممیز شناور در ثانیه در سالهای اخیر به یک پارامتر برای نمایش قدرت پردازش کارتهای گرافیک تبدیل شده که البته بیشتر ترافلاپس مورد استفاده قرار میگیرد.
مگر اینکه انویدیا هستههای RT و هستههای Tensor را برای پیاده سازیهای نسل سوم و چهارم مربوطه بازسازی کند. هستههای RT را میتوان برای تسریع نرمافزار ماشین لرنینگ در هر حوزهای که از ریاضی تانسور استفاده میکند استفاده کرد.
در همین حال، هستههای RT به راحتی میتوانند اصلاحاتی را ببینند که عملکرد RT هر هسته را ۲۵ تا ۵۰ درصد دیگر نسبت به Ampere بهبود میبخشد، درست مانند معماری Ampere که در هر هسته RT حدود ۷۵ درصد سریعتر از معماری Turing بود.

به خاطر داشته باشید که تعداد جریان چند پردازندهای ذکر شده برای تراشه کامل است و به احتمال زیاد انویدیا از تراشههای نیمه غیرفعال برای بهبود بازده استفاده خواهد کرد. Hopper H100 به عنوان مثال دارای ۱۴۴ جریان چند پردازنده بالقوه است، اما تنها ۱۳۲ جریان چند پردازنده در نوع SXM5 فعال است، در حالی که کارت PCIe 5.0 دارای ۱۱۴ جریان چند پردازنده فعال است.
احتمالاً شاهد راهاندازی جدیدی از انویدیا خواهیم بود که یک راهحل پیشرفته AD102 (یعنی RTX 4090) با چیزی بین ۱۳۲ تا ۱۴۰ جریان چند پردازنده فعال و مدلهای سطح پایینتر از جریان چند پردازنده کمتری استفاده میکنند.
ما سرعت کلاک را برای پردازندههای گرافیکی بین ۱.۶ تا ۲.۰ گیگاهرتز تخمین زدهایم که مطابق با معماریهای قبلی انویدیا یعنی Ampere ،Turing و حتی Pascal است. این احتمال وجود دارد که سرعت کلاک انویدیا بیشتر از تخمین ما باشد.

ROP یا واحد خروجی رندر (کوتاه شده render output unit)، یک جزء سخت افزاری در واحدهای پردازش گرافیکی (GPU) مدرن و یکی از آخرین مراحل در فرآیند رندر کارتهای گرافیک مدرن است. ما علامت سوال را برای ROPها (خروجیهای رندر) روی همه پردازندههای گرافیکی Ada قرار دادهایم، به خاطر اینکه هنوز نمیدانیم آنها چگونه پیکربندی شدهاند.
انویدیا در Ampere واحد خروجی رندر را به GPCها، خوشههای پردازش گرافیکی گره زد. هر GPC حاوی تعداد معینی جریان چند پردازندهای است که میتوانند به صورت جفت غیرفعال شوند. با این حال، حتی اگر تعداد جریان چند پردازندهای را هم بدانیم، نمیدانیم چگونه آنها به GPC تقسیم میشوند.
AD102 را با ۱۴۴ جریان چند پردازندهای در نظر بگیرید. این میتواند ۱۲ GPC که هر کدام ۱۲ جریان چند پردازندهای، ۸ GPC با ۱۸ جریان چند پردازندهای، یا ۹ GPC که هر کدام دارای ۱۶ جریان چند پردازندهای باشد. احتمالات دیگری نیز وجود دارد، اما این سه موردی هستند که به نظر ما محتملتر هستند.

برخی حدسها را دیدهایم که نشان میدهند GA102 دارای ۱۲ GPC از ۱۲ جریان چند پردازندهای است که حداکثر ۱۹۲ ROP را به همراه خواهد داشت. دور از ذهن نیست، اما توجه داشته باشید که Hopper H100 دارای خوشهی هشتتایی GPC از ۱۸ جریان چند پردازندهای است، بنابراین پیکربندی معقولی برای AD102 نیز به نظر میرسد.
رقم ۱۴۴ جریان چند پردازندهای برای AD102 احتمالی است. تراشه Hopper H100 دارای ۱۴۴ جریان چند پردازندهای است که از این تعداد در حال حاضر ۱۳۲ تا در سطح فعال هستند. خیلی جالب خواهد بود اگر هم Ada و هم Hopper هر دو دارای ۱۴۴ جریان چند پردازندهای باشند.
GA100 حداکثر ۱۲۰ جریان چند پردازندهای داشت، بنابراین H100 انویدیا تنها ۲۰ درصد تعداد جریانات چند پردازندهای را افزایش داده است. در مقابل، شایعات فرضی میگویند AD102 دارای ۷۱ درصد جریانات چند پردازندهای بیشتری نسبت به GA102 دارد.

لازم به ذکر و تاکید دوباره هستیم که ما در حال گزارش کردن از رقم شایعه شده ۱۴۴ جریان چند پردازندهای هستیم، اما اگر این رقم کاملاً درست نبود، تعجب نکنید. فقط به این دلیل که انویدیا هک شد و اطلاعات لو رفت است به این معنی نیست که همه چیزهایی که منتشر شده دقیق هستند. در ماههای آینده بیشتر متوجه میشویم.
آیا دوباره حافظه GDDR6X استفاده میشود؟
اخیراً Micron اعلام کرده است که نقشههایی برای حافظه GDDR6X دارد که با حداکثر سرعت ۲۴ گیگابیت بر ثانیه کار میکند. RTX 3090 Ti تنها از حافظه ۲۱ گیگابیت بر ثانیه استفاده میکند و انویدیا در حال حاضر تنها شرکتی است که از GDDR6X برای هر چیزی استفاده میکند.
این مبحث بلافاصله این سوال را ایجاد میکند که چه چیزی از از حافظه ۲۴ گیگابیت بر ثانیه استفاده میکند و به نظر میرسد تنها پاسخ معقول Nvidia Ada باشد. پردازندههای گرافیکی سطح پایینتر به احتمال زیاد به استاندارد حافظه GDDR6 میچسبند تا GDDR6X، که حداکثر سرعت آن ۱۸ گیگابیت در ثانیه است.

این ممکن نشاندهنده کمی مشکل هم باشه، زیرا کارت گرافیگها معمولاً به محاسبات و پهنای باند نیاز دارند تا مقیاس متناسبی داشته باشند و میزان عملکرد وعده داده شده را درک کنند. به عنوان مثال RTX 3090 Ti دوازده درصد محاسبات بیشتری نسبت به 3090 دارد و حافظهای با کلاک بالاتر و ۸ درصد پهنای باند بیشتر را فراهم میکند.
اگر برآوردهای محاسباتی ما از بالا حتی نزدیک به دقیق هم باشد، مشکلی وجود خواهد داشت. یک RTX 4090 فرضی میتواند حدود ۸۰ درصد محاسبات بیشتری نسبت به RTX 3090 Ti داشته باشد، اما تنها ۱۴ درصد پهنای باند بیشتری دارد. با فرض کنترل مصرف انرژی GDDR6X، فضای بیشتری برای افزایش پهنای باند در کارت گرافیگهای سطح پایینتر وجود دارد.
RTX 3050 تا RTX 3070 همگی از حافظه استاندارد GDDR6 با سرعت ۱۴ تا ۱۵ گیگابیت بر ثانیه استفاده میکنند. GDDR6 با سرعت ۱۸ گیگابیت بر ثانیه برای Ada در دسترس خواهد بود، پس RTX 4050 فرضی با ۱۸ گیگابیت در ثانیه برای GDDR6 باید به راحتی با افزایش قدرت محاسباتی برای GPU همراه شود. اگر انویدیا همچنان به پهنای باند بیشتری نیاز دارد، میتواند از GDDR6X برای پردازندههای گرافیکی سطح پایینتر نیز استفاده کند.

همچنین احتمال کمی وجود دارد که پردازندههای گرافیکی سطح بالاتر Ada با GDDR7 یا شاید «GDDR6+» سامسونگ (Samsung) که طبق گزارشها به سرعت ۲۷ گیگابیت در ثانیه میرسد، جفت شوند. با این حال، جزئیات مشخصی در مورد هیچ یک از آنها نشنیدهایم.
احتمال بیشتری وجود دارد که انویدیا نیازی به افزایش گسترده پهنای باند حافظه خالص نداشته باشد، زیرا در عوض میتواند معماری را بازسازی کند، مشابه آنچه دیدیم که AMD با RDNA 2 در مقایسه با معماری اصلی RDNA انجام داد.
حافظه نهان L2
حافظه نهان L2 یک راه عالی برای کاهش نیاز به پهنای باند حافظه خام بیشتر است، چیزی که برای دههها شناخته شده و مورد استفاده قرار گرفته میگیرد. اگر حافظه نهان بیشتری را روی یک تراشه قرار دهید، تعداد بازدیدهای حافظه نهان یا کش (Cache) بیشتری دریافت میکنید، و هر ضربه کش به این معنی است که GPU نیازی به بیرون آوردن اطلاعات از حافظه GDDR6/GDDR6X ندارد.
Infinity Cache AMD به تراشههای RDNA 2 اجازه میدهد، که کارهای بیشتری را با پهنای باند کمتر انجام دهند. اطلاعات درز شده نشان میدهد که انویدیا نیز رویکرد مشابهای را برای Nvidia Ada L2 در پیش دارد.
به نظر میرسد که معماری Ada یک حافظه نهان ۸ مگابایتی L2 را با هر کنترلر حافظه ۳۲ بیتی جفت میکند. این بدان معناست که کارتهای دارای رابط حافظه ۱۲۸ بیتی، ۳۲ مگابایت حافظه کش L2 را دریافت خواهند کرد و کارتهای رابط ۳۸۴ بیتی دارای ۹۶ مگابایت حافظه نهان L2 خواهند بود.

در حالی که در برخی موارد این مقدار کمتر از Infinity Cache AMD است، ما هنوز تاخیرها یا سایر جنبههای طراحی را نمیدانیم. حافظه نهان L2 نسبت به کش L3 دارای تأخیر کمتری است، بنابراین یک حافظه کش L2 که کمی کوچکتر باشد قطعاً میتواند با حافظه کش L3 بزرگتر اما کندتر همگام شود.
اگر به عنوان مثال به AMD RX 6700 XT نگاه کنیم، حدود ۳۵ درصد محاسبات بیشتری نسبت به نسل قبلی RX 5700 XT دارد. در عین حال، عملکرد در سلسله مراتب معیارهای GPU ما در 1440p فوقالعاده و حدود ۳۲ درصد بالاتر است، بنابراین عملکرد کلی تقریباً مطابق با محاسبات است.
6700 XT دارای رابط ۱۹۲ بیتی و تنها ۳۸۴ گیگابایت بر ثانیه پهنای باند است که ۱۴ درصد کمتر از RX 5700 XT با سرعت ۴۴۸ گیگابایت بر ثانیه است. این بدان معناست که Infinity Cache به AMD حدود ۵۰ درصد افزایش پهنای باند موثر داده است.

با فرض اینکه انویدیا بتواند نتایج مشابهی را با Ada دریافت کند، افزایش ۱۴ درصدی پهنای باند را که از طریق حافظه ۲۴ گیگابیت بر ثانیه میآید را در نظر داشته باشد و سپس آن را با افزایش ۵۰ درصدی پهنای باند مؤثر جفت کنید. این به AD102 تقریباً ۷۱٪ پهنای باند مؤثرتر میدهد، که به اندازه کافی به افزایش محاسبات GPU نزدیک است. با این حال، سلب مسئولیت بیشتر در مورد شایعات حافظه پنهان در دستور کار ما است.
مصرف برق ADA
یکی از عناصر معماری Ada که مطمئناً باعث تعجب میشود، مصرف انرژی است. Igor of Igor's Lab اولین کسی بود که با شایعاتی مبنی بر ۶۰۰ وات TBP (توان برد معمولی) برای Ada را منتشر کرد. کارتهای گرافیک انویدیا برای سالها نزدیک به ۲۵۰ وات بودند و جهش Ampere به ۳۵۰ وات در RTX 3090 (و بعداً RTX 3080 Ti) تا حدودی بیش از حد احساس میشد. سپس انویدیا مشخصات Hopper H100 را اعلام کرد و مشخصات RTX 3090 Ti را منتشر کرد و حالا شایعه ۶۰۰ وات برای Ada آنچنان بعید به نظر نرسید.

همه چیز به پایان مقیاسبندی دنارد (Dennard)، درست همراه با مرگ قانون مور برمیگردد. به زبان ساده، مقیاس دنارد (که به آن مقیاس ماسفت (MOSFET) نیز میگویند) مشاهده کرد که با هر نسل، ابعاد را میتوان تا حدود ۳۰ درصد کاهش داد. این کاهش برای سطح کلی را ۵۰٪ (مقیاس بندی در طول و عرض)، ۳۰٪ ولتاژ و ۳۰٪ کاهش تاخیر مدار نیز اتفاق میافتد. علاوه بر این، فرکانسها تا حدود ۴۰ درصد افزایش مییابد و مصرف برق کل ۵۰ درصد کاهش مییابد.
اگر چه همه اینها بیش از حد خوب به نظر میرسد اما اگر رخ دهند، به همین دلایل است که مقیاس بندی دنارد تقریباً در سال 2007 متوقف شد. مانند قانون مور، این قانون کاملاً شکست نخورد، اما برای آن دستاوردها بسیار کمتر مشخص شد. سرعت کلاک در مدارهای مجتمع تنها از حداکثر ۳.۷ گیگاهرتز در سال ۲۰۰۴ با Pentium 4 Extreme Edition به حداکثر ۵.۵ گیگاهرتز امروزی در Core i9-12900KS افزایش یافته است.
هنوز تقریباً ۵۰ درصد افزایش در فرکانس است و بیش از شش نسل (یا بیشتر) بهبود گرههای فرآیند را به همراه داشته است. به عبارت دیگر، اگر مقیاسپذیری Dennard از بین نمیرفت، CPUهای مدرن تا ۲۸ گیگاهرتز فرکانس داشتند. این فقط مقیاس فرکانس نیست که از بین میرود، بلکه مقیاس قدرت و ولتاژ نیز کاهش مییابد.

امروزه، یک گره فرآیند جدید میتواند چگالی ترانزیستور را بهبود بخشد، اما ولتاژها و فرکانسها باید متعادل شوند. اگر میخواهید تراشهای با سرعت دو برابر بیشتر داشته باشد، ممکن است نیاز به استفاده نزدیک به دو برابر بیشتر هم داشته باشید. از طرف دیگر، میتوانید تراشهای بسازید که کارآمدتر باشد، اما سریعتر نخواهد بود. به نظر میرسد انویدیا به دنبال گزینه اول با Ada است.
از یک پردازنده گرافیکی ۳۵۰ واتی Ampere مانند GA102 استفاده کنید و عملکرد را ۷۰ تا ۸۰ درصد افزایش دهید. بنابراین انجام این کار به معنای استفاده از ۷۰ تا ۸۰ درصد قدرت بیشتر خواهد بود. سپس ۳۵۰ وات به ۵۹۵ تا ۶۳۰ وات تبدیل میشود. انویدیا ممکن است کمی بهتر از مقیاسبندی خطی باشد و به احتمال زیاد ۶۰۰ وات حداکثر توان مصرفی در کارتهای مرجع خواهد بود، اما در حال حاضر شنیدهایم که برخی از کارتهای اورکلاک شده شخص ثالث نسل بعدی ممکن است شامل کانکتورهای برق دوگانه ۱۶ پین باشند.
چه زمانی سری RTX 40 انویدیا عرضه می شود؟
ما بارها به یک بازه زمانی سپتامبر برای انتشار پردازندههای گرافیکی سری Ada و RTX 40 اشاره کردهایم، اما مهم است که در نظر داشته باشید که اولین کارتهای Ada تنها بخش کوچکی از این سری خواهند بود.
انویدیا RTX 3080 و RTX 3090 را در سپتامبر ۲۰۲۰ عرضه کرد، RTX 3070 یک ماه بعد وارد بازار شد، سپس RTX 3060 Ti تنها یک ماه پس از آن وارد بازار شد. RTX 3060 تا اواخر فوریه ۲۰۲۱ عرضه نشد، سپس انویدیا این سری را با RTX 3080 Ti و RTX 3070 Ti در ژوئن ۲۰۲۱ عرضه کرد. کارت مقرون به صرفه RTX 3050 تا ژانویه ۲۰۲۲ وارد بازار نشد و در نهایت RTX 3090 Ti به تازگی در پایان مارس ۲۰۲۲ عرضه شد.
ما انتظار داریم عرضه کارتهای Ada از سریعترین مدلها شروع شود و به عرضههای گرانقیمت و جریان اصلی برسد، بهطوریکه AD106 و AD107 که بودجه محور هستند احتمالاً تا سال ۲۰۲۳ عرضه نمیشوند. همانطور که قبلاً اشاره کردیم، RTX 3050 تنها در اواخر ژانویه عرضه شد، بنابراین حداقل یک سال دیگر، جایگزینی برای آن وجود ندارد.

این سوال هنوز وجود دارد که نسل بعدی GPUهای Nvidia چه نامی خواهند داشت. اما ما با سری RTX 40 پیش رفتیم، که با الگوی ایجاد شده توسط چندین نسل گذشته بوده است، اما Nvidia همیشه میتواند نامها را تغییر دهد. یکی از دلایل تغییر میتواند «نفرت» چینیها از عدد چهار باشد، که در زبان کانتونی و ماندارین به معنای مرگ است.
این که آیا دلیل کافی برای تغییر است؟ شاید نه. مطمئناً در طول این سالها تعداد زیادی کارت گرافیک و سایر محصولات رایانه شخصی با شماره مدل «۴» دیدهایم. انویدیا پول زیادی را روی برند RTX خود سرمایهگذاری کرده است، و اگرچه اگر همه نامهای سری بعدی پردازندههای گرافیکی را حدس بزنند ممکن است چندان هیجانانگیز نباشد، اما در نهایت فروش آن چیزی است که اهمیت دارد.
کارتهای گرافیک Ada هر چه در نهایت نامیده شوند، عملکرد یا ویژگیهای آنها را تغییر نمیدهند. بسیاری از ما به طور منطقی متقاعد شدهایم که انویدیا از نامهای سری RTX 40 استفاده خواهد کرد، اما اگر انویدیا همه چیز را تغییر دهد، پایان دنیا نیست.
قیمت سری RTX 40 انویدیا چقدر خواهد بود؟
هنوز مدتی تا عرضه سری 40 RTX انویدیا فاصله داریم، بنابراین نمیتوان گفت در حال حاضر قیمت نسل بعدی چقدر خواهد بود. کارت گرافیک RTX 3060 انویدیا با قیمت ۳۲۹ دلار / ۲۹۹ پوند ارزانتر از پردازندههای گرافیکی رقیب خود یعنی سری Radeon RX 6000 AMD هستند و امید است که انویدیا این روند را با نسل بعدی کارت گرافیکهای سری 40 RTX ادامه دهد.

به احتمال زیاد، قیمت پردازندههای گرافیکی نسلی با Ada و سری RTX 40 افزایش خواهد یافت. با این حال، حافظه نهان بزرگ L2 و افزایش نسبتاً محدود در پهنای باند حافظه باید به Ada منجر شود که عملکرد ماینینگ را نسبت به Ampere افزایش دهد، درست مانند کارتهای RDNA 2 AMD فقط کمی سریعتر از مدلهای RDNA هستند.
احتمالا همه چیز بسته به این دارد که عرضه و تقاضای کارتهای موجود در ماه سپتامبر به کجا میرسد، ما تعجب نخواهیم کرد که شاهد عرضه کارتهای گرافیک برتر AD102 با قیمت پایه ۹۹۹ دلار برای مدل پایه (احتمالاً RTX 4080)، با عملکرد بالاتر «RTX 4090» باشیم. قیمت ۱۹۹۹ دلاری را RTX 3090 Ti به خود اختصاص داده است.
همانطور که در بخش بعدی بحث خواهیم کرد، دلیلی وجود ندارد که انویدیا فوراً تمام تولیدات گرافیکی خود را از Ampere به Ada تغییر دهد. احتمالاً برای مدتی طولانی شاهد تولید پردازندههای گرافیکی سری RTX 30 خواهیم بود، به خصوص که هیچ پردازنده یا پردازنده گرافیکی دیگری برای تولید 8N سامسونگ Foundry رقابت نمیکند.

واقعیت این است که قیمتها یکی از آخرین تکههای پازلی هستند که مشخص میشوند. در گذشته، ما شاهد تغییرات لحظه آخری قیمت در تعداد کمی از کارتهای گرافیک بودیم. قیمتهای RX 5700 XT و RX 5700 AMD به ترتیب با قیمتهای ۴۹۹ و ۳۹۹ دلاری به مطبوعات معرفی شدند و یک هفته بعد برای عرضه واقعی به ۳۹۹ و ۳۴۹ دلار کاهش یافتند.
نسخه Founders EDITION
Nvidia در هنگام معرفی RTX 3080 و 3090 ادعاهای زیادی در مورد طراحی کارت Founders Edition جدید خود داشت. در حالی که به طور کلی کارتها معمولاً خوب کار میکنند، چیزی که ما در ۱۸ ماه گذشته کشف کردهایم این است که کارتهای خنک کننده با استفاده از قدرت بیشتر، آرام تر کار کنند. GeForce RTX 3080 Ti Founders Edition نمونهای آشکار از این بود که چگونه دما و سرعت فن نمیتوانند با پردازندههای گرافیکی داغتر سازگار شوند.
اکنون، مصرف برق شایعه شده را در نظر بگیرید که تقریباً دو برابر چیزی است که در برخی موارد با معماری Ampere دیدیم، و تصور اینکه انویدیا به طراحی صنعتی فعلی پایبند باشد، دشوار است. اگر انویدیا واقعاً با یک قطعه ۶۰۰ واتی در حال کار باشد، باید خنک کنندهای استثنایی برای از بین بردن گرما فراهم کند، و در حالت ایدهآل آن را از کیس خارج کند.
هیچ اطلاعاتی از شکل کارتهای Ada منتشر نشده است، چه از طرف Nvidia چه از طرف شرکای آن. البته این کاملا منطقی است، زیرا هنوز چند ماه با در دسترس بودن آن فاصله داریم. احتمالاً یک یا دو ماه قبل از عرضه رسمی تصاویر منتشر شده را دریافت خواهیم کرد.
همچنین اگر به دنبال بهترین و کارآمدترین برنامه تغییر دی ان اس هستید، این مقاله را از طریق این لینک بخوانید.
بیشتر بخوانید:


دیدگاهها و نظرات خود را بنویسید
برای گفتگو با کاربران ثبت نام کنید یا وارد حساب کاربری خود شوید.
مجموع نظرات ثبت شده (5 مورد)
مطالب پیشنهادی

 مطالب مرتبط از نگاه دیجیاتو
مطالب مرتبط از نگاه دیجیاتو








تنها چیزی که ازش میدونم اینه که تو خوابمم نمیتونم بخرمش:/
با تشکر از خانم وکیلی برای این مقاله مفید و کار آمد
فکر کنم یه نیروگاه کوچیک برق اونایی که می خوان بخرن این کارت باید داشته باشن??
خدا تومن می شه قیمتش !!
باید هم بشه